大模型驱动云计算需求激增,Arm拿出新应对之策
 随着全球云计算巨头纷纷提出自研AI芯片计划,各类型计算产业链公司都迎来巨大发展机会。 虽然目前最为瞩目的是GPU巨头NVIDIA,但AI芯片计算需求不仅限于强于并行计算的GPU,还包括主打通用计算的CPU、专用芯片ASIC等。因此相关公司都在不断攻坚提升芯片性能。 近日Arm高级副总裁兼基础设施事业部总经理Mohamed Awad接受21世纪经济报道等记者采访时分析,目前在云服务商对AI的极大兴趣驱动下,和AI相关的计算需求非常庞大,但传统的通用CPU已无法满足AI相关计算需求。而云服务商自主设计芯片过程中,也需要考虑这些芯片都能运行目前市面上已有的软件。 “我们看到合作伙伴正构建与AI加速器紧密耦合的定制通用计算,这在Arm与NVIDIA Grace Hopper、亚马逊云科技 (AWS) 以及微软的合作中都有所体现。此外,这一趋势也正发生在许多中国合作伙伴的项目上,他们在开发加速器的同时,还致力于协同设计通用计算。”他续称。 自研芯片趋势明显从整体趋势看,Arm 基础设施事业部产品解决方案副总裁Dermot O’Driscoll指出,AI芯片行业正呈现两个特征:其一,人们希望对支持云计算关键工作负载的计算进行优化;其二,头部企业正在打造定制芯片,并需要有效的方式来实现。 Mohamed Awad进一步分析,“基础设施所需处理和管理的数据和计算量相当大,加上AI等新工作负载的计算需求又非常高。这意味着通用的现成芯片很难优化到能够支持基础设施日益增长的需求。数据中心提供商和头部云服务提供商正在重新设计整个服务器、机架和仓库,从而获得更佳的性能、效率和总体拥有成本 (TCO)。这一切驱使他们从定制芯片着手。” 他具体举例道,在基础设施领域,看到转型持续朝向更复杂的仓库级计算,它不再只关乎芯片、服务器或机架,而是关乎整个数据中心。 “NVIDIA就是很好的例子,其推出的Grace Hopper从根本上重新设计了系统架构。在这一设计中,从单个CPU管理多个GPU,转变为CPU与GPU一对一映射。更多CPU意味着内存一致性,最终会大大提高GPU的利用率。”他指出,AWS和微软等巨头也采取了类似方法,从头开始设计系统,并从定制系统级芯片 (SoC) 开始。因为他们比任何人都更了解自己的工作负载,可以对系统各方面进行调优,包括网络、加速甚至是通用计算,以优化效率、性能和TCO。 “去年我们推出了Arm Neoverse计算子系统(CSS),使定制芯片更迅速且易实现。”Dermot O’Driscoll介绍,在Neoverse CSS中,Arm负责配置、优化和验证一套完整的计算子系统,并针对基础设施市场的各种关键用例进行配置,从而让合作伙伴能够专注于针对特定系统级工作负载塑造差异化竞争优势,比如软件调优、定制加速等。此外,客户还能加速产品上市时间、降低工程成本。
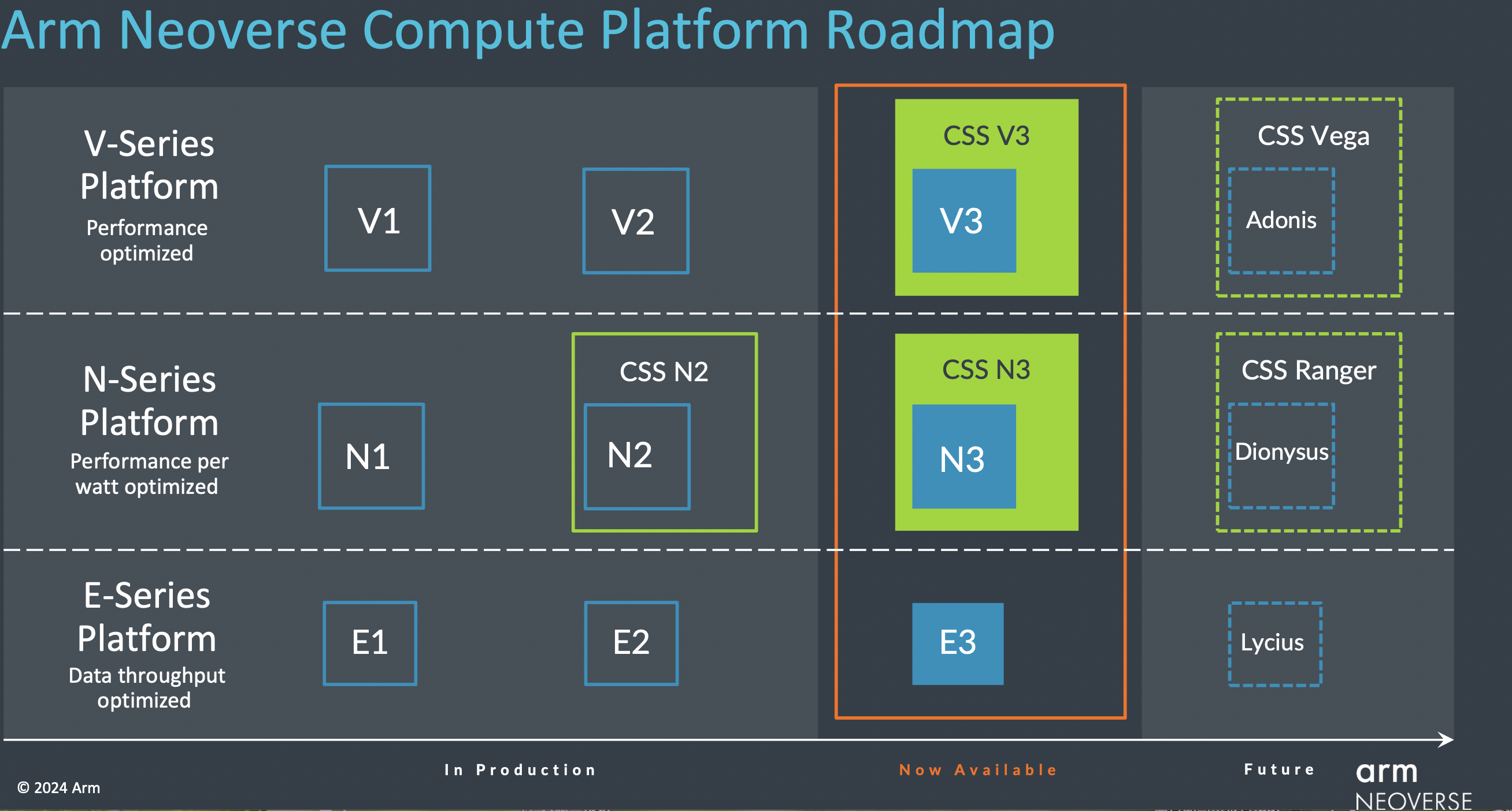
近期Arm宣布推出两款基于第三代Neoverse IP构建的新Arm Neoverse CSS,即Arm Neoverse CSS V3和Arm Neoverse CSS N3。其中Arm Neoverse CSS V3与CSS N2相比,单芯片性能可提高50%;Arm Neoverse CSS N3与CSS N2相比,其每瓦性能可提升20%。 当然,AI的适用范围不仅是应用服务器和数据中心。AI正成为包括网络、安全和存储等诸多领域不可或缺的一部分,它可应用到包括小型终端到交换机、路由器和基站等各种设备在内的整个基础设施中。Mohamed Awad表示,凭借新的CSS N3和CSS V3,Arm专注于释放芯粒等新技术的潜力,并更大限度优化实际工作负载的TCO。 软硬件适配的重要性当然也正因为自研芯片参与者众多,导致相关AI芯片从设计、流片到最终商用落地的过程,将涉及与不同软件、接口等匹配,同时如何节省能耗也尤为重要。 Dermot O’Driscoll受访时介绍,在算力需求持续增长下,意识到算力也受到成本和能源的限制这一点很重要。这也驱动了在数据中心和基础设施中自上而下的优化,并带来越来越多专为软件工作负载量身打造定制芯片的需求。 “在构建Neoverse N3和V3平台时,Arm也与合作伙伴紧密合作,了解他们的软件需求并针对这些需求提供优化。我们的CSS和IP平台意味着合作伙伴可以更加灵活地根据特定需求进一步优化设计。”他续称,“同时,我们一直在与合作伙伴一起构建和优化云原生软件。我们从早期就将软件栈和工作负载迁移到Arm平台的合作伙伴那里,得到的反馈是,整个迁移过程比预期容易。” 在应用场景方面也有新的趋势表现。Dermot O’Driscoll分析道,目前行业重点更多放在训练LLM(大语言模型)上,但随着生成式AI广泛应用于实际业务场景,其工作重点将转向推理。有分析师估计,已部署的AI服务器中有高达80%专用于推理,这一数字还将持续攀升。 近期NVIDIA财报会上也提到,在去年第四财季,其数据中心类业务中,约有40%收入是用于AI推理所产生。 这一转变意味着要找到合适的模型和模型配置,并加以训练,然后将其部署到更具成本效益的计算基础设施上。吞吐量是其中一部分考虑因素,当然还有其他因素。 Dermot O’Driscoll表示,CPU广泛可用,并可灵活用于ML(机器学习)或其他工作负载,此外,CPU还易于部署,并可支持各种软件框架,具备低成本和高能效等优势。因此,CPU推理将是生成式AI计算应用的关键组成。但显然,也并非所有AI处理都将在CPU上进行。 “NVIDIA Grace Hopper的一大关键创新在于内存容量和共享内存模式。这种紧耦合的CPU加上加速器配置,对大参数LLM非常有益,对检索-增强-生成 (RAG) 等新兴方法也很有帮助。Arm推出的Neoverse CSS能提供客户所需的所有接口,以便选择耦合自身的加速器。这种方法既可以在需要CPU时提供CPU,又可以在需要AI加速器时提供AI加速器,做到两全其美。”他指出。 在Neoverse CSS基础上,去年10月,Arm全面设计(Arm Total Design) 生态项目推出,围绕Arm计算子系统开展创新设计。Arm基础设施事业部营销副总裁Eddie Ramirez则介绍,在推出后四个月内,Arm全面设计生态项目已有20多家成员加入。其中包括新的EDA和配套IP提供商以及来自各个战略市场的芯片设计合作伙伴。 (编辑:admin) |
 汇川技术骆梦龙:
汇川技术骆梦龙: 安徽建工集团:智
安徽建工集团:智 Salesforce与谷歌达成
Salesforce与谷歌达成 阿里巴巴将投入
阿里巴巴将投入 “阿里云+云计算
“阿里云+云计算